
The Good Life (Enron Simulator) by Sam Lavigne and Tega Brain was awarded a 2016 Rhizome Net Art Microgrant. The artwork recreates the experience of receiving all 500,000 emails from the Enron email archive via a chronological timescale of the viewer's choosing. The signup page for this work is now on view on the front page (desktop only).
The Enron email archive is a corpus of more than 500,000 emails, written between 158 senior executives of the Enron corporation during the last years of the company’s operation. In March of 2003, following revelations of Enron’s spectacularly corrupt business practices and subsequent demise, these emails were deemed public domain and released online by the Federal Energy Regulatory Commission (FERC). This was the first release of an email database of this size, and it remains one of the only large public domain email collections easily and freely accessible online. As Finn Brunton, author of Spam: A Shadow History of the Internet, observes, “The FERC had thus unintentionally produced a remarkable object: the public and private mailing activities of 158 people in the upper echelons of a major corporation, frozen in place like the ruins of Pompeii for future researchers.”1 The corpus has since become a uniquely valuable linguistic resource for computer scientists who have used it to train spam filters and other natural language machine learning systems. This dataset, which was generated by a group of mostly white male corporate criminals, is therefore in our lives in ways we don’t understand and haven’t fully considered.
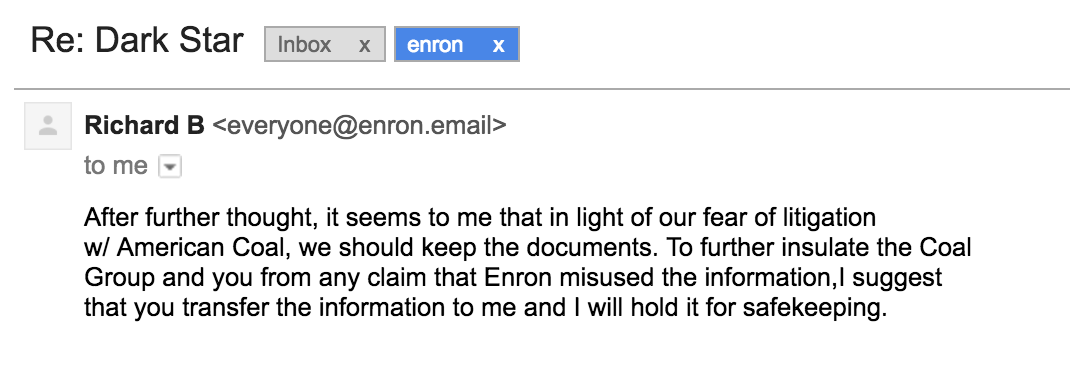
Email from the Enron corpus, June 10th 1999.
In 2001 the Enron Corporation’s stock price plummeted from a high of $90.75 to less than $1 after revelations of the company’s corrupt business practices, which included price fixing, misrepresentation of earnings, and massive accounting fraud. Roughly a year later, Enron declared one of the largest bankruptcies in American corporate history. During the subsequent investigations, the FERC acquired all Enron company data, and released their email archive online in early 2003.
The archive originally contained more than 1,600,000 emails. However, following complaints by Enron employees, the FERC agreed to remove emails containing personal information deemed irrelevant to the public good. In October of 2003 the database was taken offline for 10 days to allow 100 Enron employees to identify such email and as the Wall Street Journal reports, each “was given a chunk of files to search, looking for such terms as ‘Social Security number,’ ‘credit card number,’ and ‘divorce.’ The company gave raffle prizes—Houston Astros tickets and Enron T-shirts—to those who did the most searching. The grand prize was a day off.”2

Email from the Enron corpus, January 1999.
Beyond its historical significance as a record of one of the largest financial scandals in history, the corpus emerged as an invaluable technical resource for researchers studying email, communications and language. Until the more recent Wikileaks email releases, the Enron corpus was the only sizable, publicly available dataset of real emails sent between a large group of people. As such, its applications have been pervasive and widespread. MIT’s Technology Review reports that “much of today’s software for fraud detection, counterterrorism operations, and mining workplace behavioral patterns over e-mail has been somehow touched by the [Enron] dataset.”3
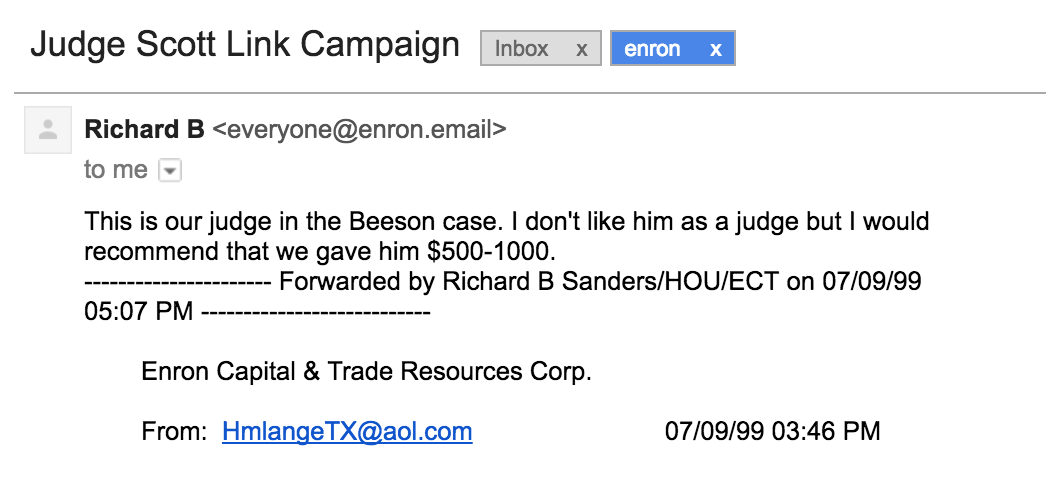
Email from the Enron corpus, July 1999.
Academics continued the painstaking work of culling and tagging the corpus for years after its release in a monumental collaborative effort to produce the cleanest and most research-friendly archive possible. The version we are using in The Good Life (accessible here) was made available by William W. Cohen, professor of computer science at Carnegie Mellon, and last updated in 2015.
We live in an era where machine learning is fast becoming ubiquitous. It is deployed in technologies used by the military and law enforcement agencies, and it controls how we encounter online content like news, search results, advertising, music, and dating recommendations. The Enron email dataset has had a hand in training many of the machine learning systems that mediate our online communications. It was initially used in email sorting engines before email providers built up sizable private corpus from their own user bases, and it was also used in the genesis of Apple’s Siri, which descended from the DARPA-funded “Cognitive Assistant that Learns and Organizes” project.3 Machine learning systems inevitably reproduce the patterns and biases existing in the data used to train them. The Enron corpus therefore reminds us that we need to be asking questions of who is represented in training datasets, what bias this produces, and how these systems then go on to be used.
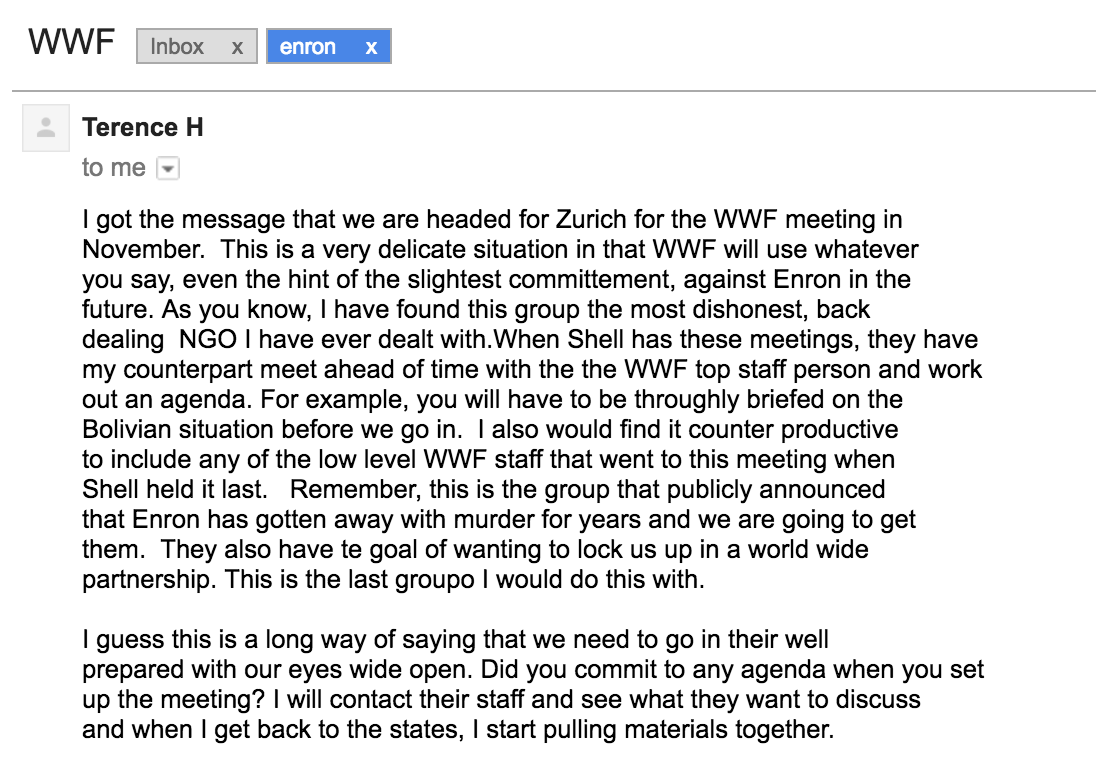
Email from the Enron corpus, October 1999
The actual content of the Enron emails encompasses a wide gamut of human emotion and activity. They document tedious office politics, relentless meeting scheduling, deeply embarrassing romantic drama, misogynist jokes, chain-emails, reflections on life as a corporate executive in 1999, and, of course, revelations of large-scale corporate malfeasance and fraud.
The Enron release heralded the contemporary positioning of email as an ongoing record of our everyday activities, one we increasingly risk being held accountable to via leaks and disclosures. As the events of the recent election show, emails can become highly contested datasets of deep significance. They are a medium where power is distributed, where the personal becomes political. To experience the Enron simulator is to witness the inner workings of a corporate America in which those on top get richer and moral and ethical obligations are eschewed for tremendous personal gain. We see firsthand the minutia of producing and maintaining inequality.
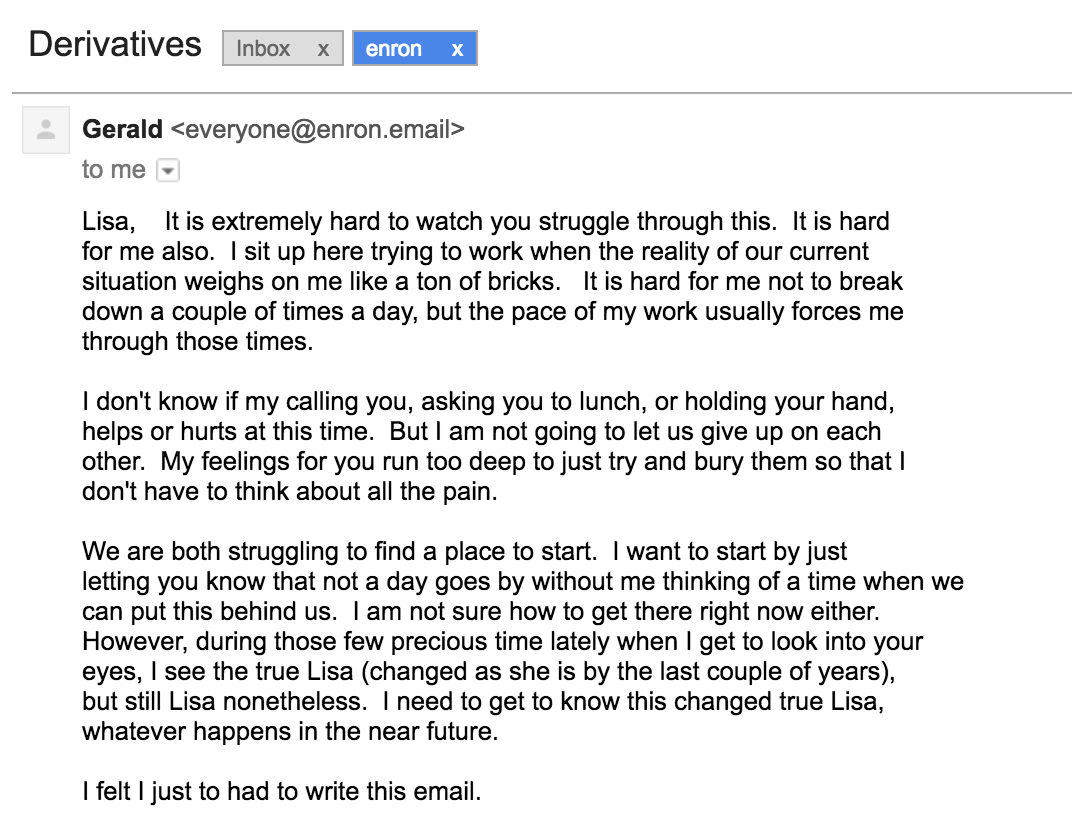
Email from the Enron corpus, August 1999
The Good Life invites you to experience a nightmarish simulation of living through the death throes of a corporation in the 2000s. Sign up at http://enron.email to receive all 500,000 Enron emails over the course of five days, thirty days, one year or seven years. You will receive the emails in chronological order at the frequency at which they were sent, relatively adjusted to the timeline you select.
There are many ways to enjoy the Enron corpus, but by far the most pleasurable is to read all 500,000 emails in the order they were sent.
References
1. Brunton, Finn. Spam: a shadow history of the Internet. MIT Press, 2013.
2. Berman, Dennis K. “Government Posts Enron's E-Mail.” Wall Street Journal, 06 October 2003. Web. 18 Nov. 2016.
3. Leber, Jessica. "The Immortal Life of the Enron E-mails." MIT Technology Review. MIT, 02 July 2013. Web. 18 Nov. 2016.
Featured image: Downtown Houston, Enron Building by JWSherman on Flickr